You are not alone if you have only heard "vector database" for the first time. Although vector databases have been around for a few years, they have only lately captured the attention of the broader developer community.
The release of ChatGPT has heightened interest in vector databases. Since late 2022, the general public has begun to appreciate the possibilities of cutting-edge large language models (LLMs), while engineers have learned that vector databases can further enhance these models.
But what do vector databases and their core concepts, such as vector embeddings and vector search, mean? Let’s dive into the details.
What is a Vector Database?
A vector database indexes, stores, and offers access to organized or unstructured data (such as text or images) and its vector embeddings, which are numerical data representations. It enables users to identify and retrieve similar objects at scale in production swiftly.
Vector embedding is a data encoding that contains semantic information that helps AI systems interpret the material and preserve long-term memory. Understanding and remembering the content are the most critical aspects of learning anything new.
Key components of vector databases
So, what are the core components of vector databases? A vector database can include the following fundamental components:
Performance and fault tolerance: The techniques of sharding and replication ensure that a vector database is both performant and fault resilient. Sharding includes splitting data over several nodes, whereas replication requires producing multiple copies of data across numerous nodes. If a node fails, this offers fault tolerance and continuing performance.
Monitoring capabilities: To maintain performance and fault tolerance, a vector database must monitor resource utilization, query performance, and overall system health.
Access control capabilities: Vector databases require data security management and access control capabilities. Regulation of access control guarantees compliance, accountability, and the ability to audit database usage. It also indicates that data is secure: It is only accessible to those with the necessary rights, and a record of user activity is retained.
Scalability and tunability: Its access control features influence a vector database's scalability and tunability. The capacity to scale horizontally becomes increasingly important as data storage grows—different insert and query rates and variances in the underlying technology influence application requirements.
Multiple users and data isolation: Besides scalability and access control, a vector database should support numerous users or multi-tenancy. In addition, vector databases should have data isolation so that any user action (such as inserts, deletes, or queries) stays private to other users until otherwise necessary.
Backups: Vector databases produce frequent data backups. In the event of a system failure, backups can assist in restoring the database to its earlier state. It cuts down on downtime.
APIs and SDKs: APIs are used in vector databases to offer a user-friendly interface. An API is an application programming interface, or software, that allows programs to "talk" to each other by sending and receiving requests and answers.
Vector database vs traditional database
But how do they differ from traditional databases? Traditional relational database systems are good at maintaining structured data in prescribed forms and performing exact search operations.
Vector databases, on the other hand, specialize in storing and retrieving unstructured data types, including photos, music, videos, and textual information, using high-dimensional numerical representations called vector embeddings.
Vector databases look for similarities using techniques like the Approximate Nearest Neighbor (ANN) algorithm. They are widely used in developing apps in various disciplines, including recommender systems, chatbots, and tools for searching for comparable photos, videos, and audio content.
With the growth of AI and large language models (LLMs), including ChatGPT, vector databases come in handy to tackle LLM hallucinations.
What are vector embeddings?
Now, let’s talk about vector embeddings.
Most people think about data and see nicely arranged numbers on spreadsheets. This data is called structured data since it can be conveniently recorded in a tabular fashion. However, 80% of recent data is estimated to be distorted.
Instances of unstructured data contain text (docs, social media posts, or e-mails), pictures, and time series data (e.g., audio files, sensor data, or video). The issue with unstructured data is that it is difficult to organize so you can readily discover what you are searching for.

However, advances in Artificial Intelligence (AI) and Machine Learning (ML) have enabled us to mathematically represent unstructured data in vector embeddings without losing semantic value. A vector embedding is a lengthy list of integers, each describing a different aspect of the data object.
AI systems, like LLMs, create embeddings with various features that redefine their portrayal as difficult to adapt. Embedding resonates with the viral aspects of the data, assisting AI models in understanding various relationships, patterns, and hidden structures.
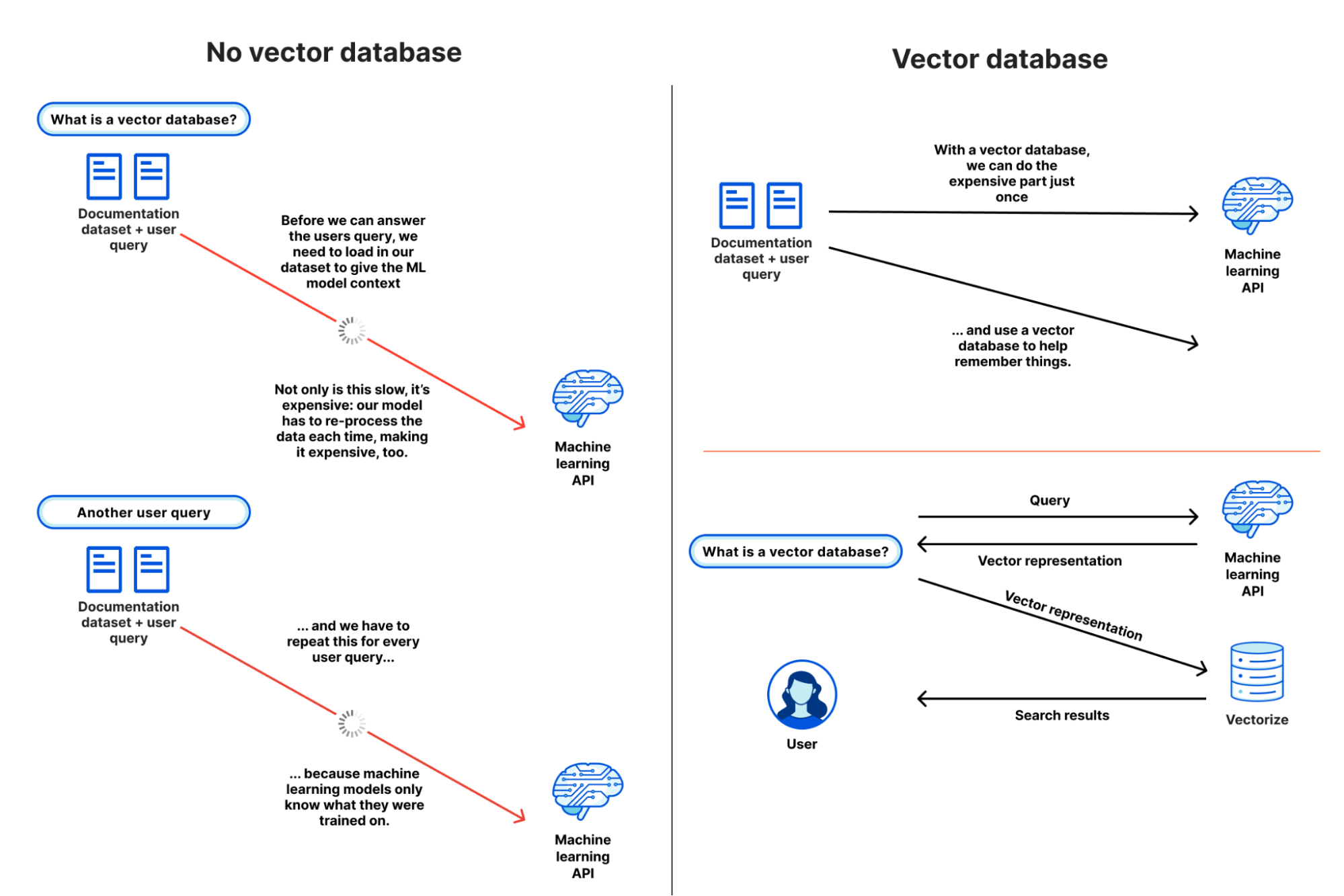
How does a vector database work?
We know how traditional databases store texts, integers, and other scalar data in rows and columns. A vector database, on the other hand, functions on vectors. Therefore, the way it is optimized and searched is somewhat different.
In traditional databases, we often look for rows where the value fits our query exactly. A similarity measure is used in vector databases to locate the most similar vector to our query. A vector database employs various techniques, all participating in the Approximate Nearest Neighbor (ANN) search.
These algorithms improve search results using hashing, quantization, or graph-based search. These techniques are combined into a pipeline that allows rapid and accurate retrieval of a vector's neighbors.
Because the vector database produces approximations, the key trade-offs we examine are accuracy against speed. The faster the query, the more accurate the result. A good system, on the other hand, can offer ultra-fast search with near-perfect precision.
Here's an example of a vector database pipeline:

Indexing: Vectors are indexed in the vector database using a method such as HNSW, PQ, or LSH. It converts the vectors into a data structure, allowing faster searching.
Querying: The vector database matches the indexed query vector to the indexed vectors in the dataset to locate the closest neighbors (using the index's similarity measure).
Post-processing: In some circumstances, the vector database obtains the dataset's final nearest neighbors and post-processes them before returning the final results. This phase can involve re-ranking the closest neighbors based on a different similarity metric.
Why are vector databases important?
For use cases, including similarity search, machine learning, and AI applications, vector databases provide significant benefits over regular databases. Here are a few advantages of vector databases:
High-dimensional search: Similarity searches on high-dimensional vectors can be performed quickly via vector databases, extensively used in machine learning and AI applications such as image recognition, natural language processing, and recommendation systems.
Scalability: Vector databases can grow horizontally, effectively storing and retrieving enormous volumes of vector data. Scalability is critical for applications that demand real-time search and retrieval of enormous volumes of data.
Flexibility: Vector databases can handle many vector data formats, including scatter & dense vectors. They can maintain various data kinds, such as text, binary & numerical ones.
Performance: Vector databases execute similarity searches quickly, typically outperforming conventional databases.
Customizable indexing: Indexing algorithms can be customized for individual use cases and data types in vector databases.
Overall, vector databases provide considerable benefits for similarity and machine learning applications by allowing for rapid and efficient search and retrieval of high-dimensional vector data.
How Vector Databases Help Boost AI?
One of the most significant advantages vector databases provide to AI is the ability to use current models across vast datasets through quick data access and retrieval for real-time operations. A vector database is the foundation for memory recall, the same memory recalls our organic brain employs.
Artificial intelligence is divided into cognitive processes (Large Language Models), memory recall (Vector Databases), specific memory engrams and encodings (Vector Embeddings), and neurological pathways (Data Pipelines) via vector databases.
These mechanisms, when combined, allow artificial intelligence to smoothly learn, evolve, and access knowledge. The vector database stores all memory engrams and allows cognitive functions to recall material that generates comparable experiences. When an event occurs, our brain recalls other occurrences that evoke the same sentiments of joy, grief, fear, or hope.
When tapped into a nervous system, data pipelines that allow new memories to be stored and retrieved as they are made, AI models can learn and grow adaptively by indulging in workflows that offer entire history, overall analytics, or factual information.
Applications of vector databases
Businesses must process, store, and retrieve massive volumes of data quickly and effectively. Vector databases are an important new technology for meeting this requirement. Instead of typical ones, Vector databases focus on HD vector data, providing distinct benefits for certain use cases.
1. Image and Video Recognition
Given the large dimensionality of images and videos, vector databases are naturally suitable for similarity search within visual data. For example, companies with large picture files may utilize vector databases to locate related images, making duplication detection and image classification easier.
2. Natural Language Processing (NLP)
Words/phrases in Natural Language Processing (NLP) are defined as vectors using embeddings. Finding semantically comparable texts or classifying vast amounts of textual data based on similarity becomes possible using vector databases.

3. Recommendation Systems
Whether for movies, music, or e-commerce items, recommendation systems frequently rely on identifying the similarity between user preferences and item attributes. Vector databases can speed up this process, allowing real-time, tailored suggestions.
4. E-commerce Personalization
Imagine a clothing-selling e-commerce platform. Each product can be depicted as a high-dimensional vector based on qualities such as color, style, fabric, and customer feedback. When a user browses a product, the system may swiftly search the vector database for things with similar characteristics and provide customized product recommendations.
5. Biometrics and Anomaly Detection
Biometric data is high-dimensional and requires effective similarity search capabilities, from face recognition systems to fingerprint databases. Similarly, vector databases can help anomaly detection in systems like network security, where "normal" patterns are vectors, and deviations or abnormalities can be promptly discovered.
Future trends in vector databases
The development of AI and ML and research into the application of deep learning to build increasingly powerful embeddings for structured and unstructured data are all intertwined with the future of vector databases.
Vector databases' future provides intriguing potential for further growth and integration:
Enhanced Data Integration: Vector databases can be connected with current database systems, allowing for more complete data analysis and insights.
Continued AI Advances: The collaboration of vector databases with AI technology can lead to more efficient algorithms and enhanced data analysis capabilities. Distributed architectures, advanced vectorization techniques, and others will be widespread.
Industry Application Expansion: Vector databases can be used in various industries, including healthcare, banking, logistics, and manufacturing, to enable more effective and data-driven decision-making processes.
Wrapping Up
With the fast expansion & gearing up generative AI over multiple industries, we require a purpose-oriented model to store the huge amounts of data necessary to drive contextual decision creation.
Vector databases were created specifically for this purpose, and they offer a unique answer to the problem of handling vector embeddings for AI use. The ability to permit contextual data at rest and in motion to give the fundamental memory recall for AI processing is where a vector database's actual power lies.
As AI continues to evolve and new systems are published weekly, the rise of vector databases plays an important role. So, the next time you enter a query in ChatGPT or Google Bard, consider the steps it takes to return a response for your query.
Informative